Analyzing access to S3 buckets

A robust AWS incident response plan tends to begin with CloudTrail. CloudTrail is a tool that enables insight into events that occur within the AWS account. It is the first step in investigating a breached account and generally provides a wealth of information. In many cases, however, CloudTrail will not answer all of the questions.
Recently, during an Incident Response engagement, we were tasked with understanding the actions that a Threat Actor (“TA”) took inside an AWS account. We quickly encountered some roadblocks as the account did not provide sufficient logging. In particular, we suspected that the TA had been exfiltrating data from S3, but we were unable to verify it. In fact, we couldn’t distinguish between the normal behavior of the access keys versus the attacker behavior simply because we did not have the visibility we needed.
In this post, we’re going to dig in and explore CloudTrail data events and other tools which can enable better investigation into S3 buckets.
To set the stage a bit, let’s assume that an actor has compromised a set of AWS access keys used for legacy production workloads, and that may not be easy to rotate. To understand what these keys are doing, there are a few options:
- IAM AccessKey Overview page: This page displays the last service that an access key has interacted with but does not provide any additional information. It is an extremely minimal view but can shed some light on the environment and activity.
- CloudTrail: CloudTrail will provide a significant amount of information related to API calls that have been invoked by the access key.
CloudTrail Data Events
Cloudrail data events are events that typically generate a large volume of events, for instance, s3:getObject. By default, these events are not logged with CloudTrail and have to be explicitly enabled.
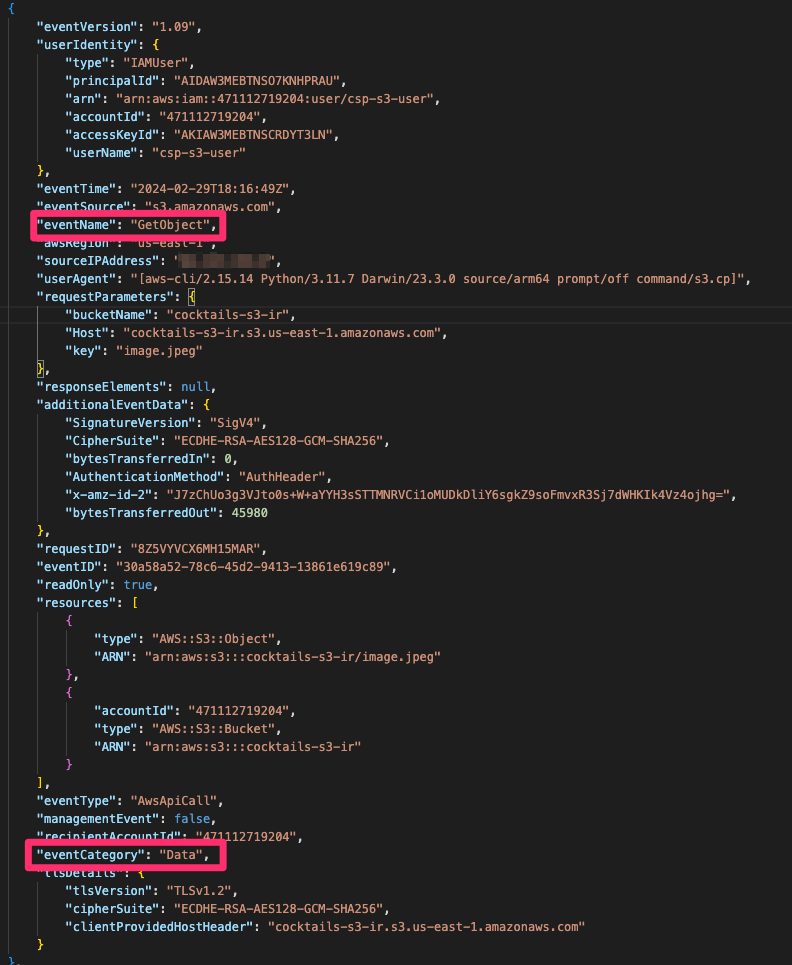
Reviewing the CloudTrail log above provides a wealth of information related to the activity. In this case, we clearly see that a data event has been recorded for the GetObject event. This entry includes the user identifier, access key, user agent, and more pertaining to the principal.
Server Access Logging
S3 Server Access Logging is a best-effort access logging tool for S3. This generally means that there is no guarantee that every request will be accounted for, and sometimes, requests will be logged in duplicate. As an incident responder, understanding that there could (while, in my experience, unlikely) be gaps in the log files can cause concern, as it may not be possible to understand the full picture.

By reviewing the sample Server Access Log above, we can see that it provides a lot of information, such as Source IP address, timestamp, User Agent header, and the user identifier. One useful piece of information, which is not included, is the access credentials used to make the request. If the user had multiple access keys enabled we would be unable to determine which of those keys made the request.
With little work, server access logs can be ingested and queried directly with AWS Athena: https://repost.aws/knowledge-center/analyze-logs-athena
Best Practices
Providing better visibility from an IR perspective for S3 objects can be an easy task to accomplish in many environments. Like most things, there is a cost tradeoff between dramatically increasing the size of our logging infrastructure and providing the visibility we need. To help make that decision, I generally recommend working through the following checklist:
- Enable server access logging on all buckets (except the bucket storing these logs, of course).
- Does the account make substantial use of S3 or other data-generating events?
- If not, associated costs are likely to be minimal, and I recommend ensuring that CloudTrail data events and S3 server access logging are enabled for all buckets.
- Are there buckets that are particularly sensitive, such as customer records?
- In these cases, it’s going to be extremely important to be able to comprehensively audit access (both request and modification) to associated objects. In this case, ensure that the associated buckets have both S3 server access logging as well as Cloud Trail data events enabled for the associated buckets. While this approach will not provide full visibility across the account, we can balance the log storage costs by only ensuring that we’re focusing on the sensitive data at hand.
For more recommendations, I highly recommend checking out https://ramimac.me/s3-logging
If you need help strengthening your organization's preparedness for incident response, feel free to contact us at Cloud Security Partners. We work with organizations across many industry verticals to ensure they have adequate coverage to perform a successful incident response investigation.
_________________________________________________________
John Poulin is CTO of Cloud Security Partners. John is an experienced Application Security Practitioner with over 10 years of experience in software development and security. Over his tenure, John has worked with many Fortune 500 companies and startups alike to perform secure code reviews, architecture, and design discussions, as well as threat modeling.