Introduction to LLM Security

In the dynamic world of AI today, Large Language Models (LLMs) stand out as one of the most interesting and capable technologies. The ability to answer arbitrary prompts has numerous business use cases. As such, they are rapidly being integrated into a variety of different applications. Unfortunately, there are many security challenges that come with LLMs that may not be well understood by engineers.
Here at Cloud Security Partners, we’ve performed several engagements on applications that integrate LLM technology, many of which contain unsafe and insecure patterns. These issues range from insecure design to insecure configurations.
Securely designing LLM integrations is a very broad and rapidly evolving field. However, there are several types of vulnerabilities that we commonly see in many implementations.
In this multipart blog series, we will cover the security of Large Language Models in four parts; we’ll cover what LLMs are, some novel attacks on LLMs, and finally go over how to threat model and properly design an application that uses LLMs.
What is an LLM?
A Large Language Model, like ChatGPT, is a type of Neural Network that is trained to understand and generate human-like language. For more technical readers, the basic concept is similar to a Markov chain. It works by passing the input through a Markov model and generating the next most likely word. It does this for the entire output, using a process similar to the below:
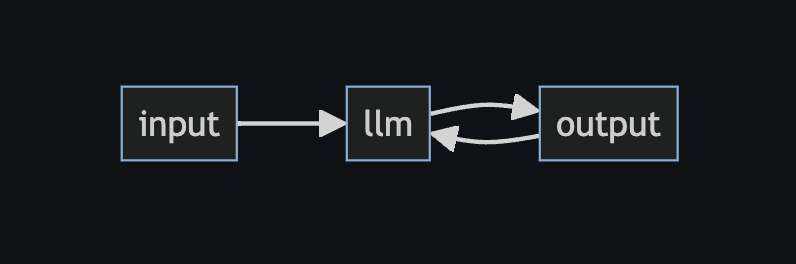
From a security perspective, an LLM is typically just another cloud SaaS service. The vast majority of use cases do not involve an on-premise LLM (due to performance and cost considerations), and instead make an API call to a foundation model offered as a service, such as GPT, LLaMa, or Claude. As such, we can typically model an LLM as a black box that takes some input, has some data accessible to it, and produces some arbitrary (user-controlled) output.
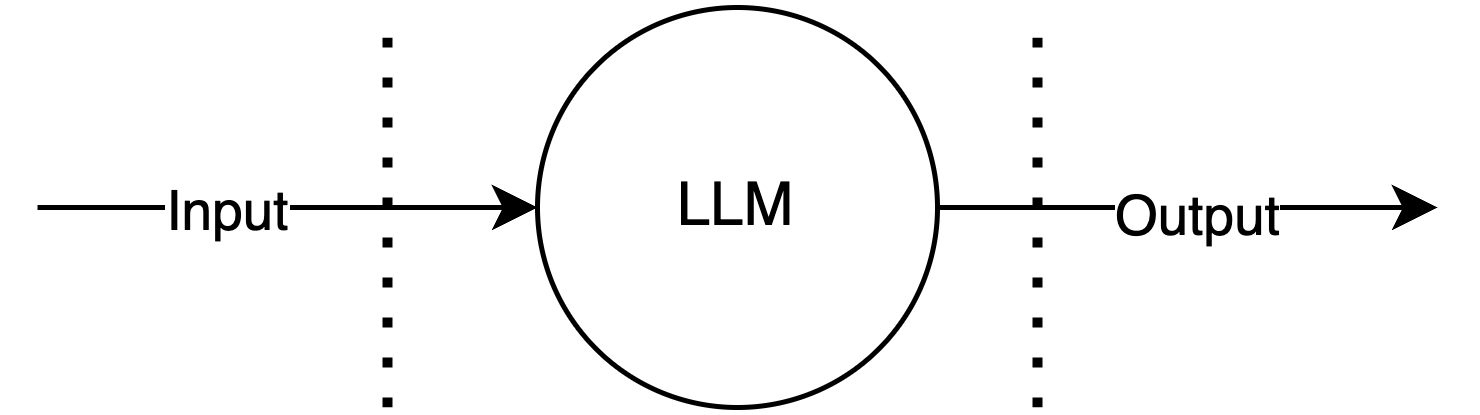
Note the trust boundaries around the LLM call, similar to any other cloud API that might be integrated into your application.
What isn’t an LLM?
It is important to note that, despite the astonishing progress made in the past two years, there are technical restrictions on what LLMs are capable of.
As explained previously, LLMs are Markov processes. As such, the output of an LLM is not the result of a deep semantic understanding of the world, it is simply returning one of the most likely answers for a given prompt. This distinction is important to note; as an LLM doesn’t have a semantic understanding of the world, it is incapable of knowing exactly what it does not know, nor what it should not know. From a security perspective, this means that they are (a) often incorrect and (b) can be tricked by a malicious user. In other words, they fail open in a manner that is known as hallucination.
Due to the above technical reasons, LLMs cannot be blindly trusted without applying some oversight. As such, we must carefully architect systems using LLMs to prevent security vulnerabilities. We will discuss the impact of overreliance on LLM systems further in a future blog post.
How Does LLM Security Differ From Traditional Web Security?
Most traditional security challenges still apply to LLMs. As a cloud service, you need to secure your infrastructure in the same exact way. Proper logging and monitoring, authorization, and Denial of Service are all things to watch out for when integrating an LLM into your environment. Furthermore, an LLM is typically integrated into a larger application, so one must ensure API and traditional application security in the broader app.
However, due to the nature of LLMs as a machine learning algorithm, there are a few unique emergent vulnerabilities. Data poisoning and data leakage are two vulnerabilities that are common to all machine learning applications, including LLMs:
- Data poisoning occurs due to malicious users being able to insert data into the training dataset, which may be able to influence the model in unexpected ways. Due to the size of training data required to create a foundation model such as GPT4 or LLaMa, not all data that is used to train it can be properly vetted. As such, one must always be aware of the possibility of an LLM returning malicious or otherwise bad data.
- Data leakage occurs due to models partially memorizing input data. Due to their simplistic and trusting nature, anything that a model has access to or was trained on can be accessed by a malicious user. This includes any embeddings that are available through Retrieval Augmented Generation, as well as any data that was used to fine tune an LLM, and also to any data that was part of the initial corpus the LLM was trained on.
Finally, there are a couple of classes of vulnerabilities that occur due to design errors when integrating an LLM into an environment. These include prompt injection, overreliance on LLM output, and insecure output handling. All input and output into an LLM should be treated as user-controlled, and as such, overly trusting these parameters will lead to security flaws.
We will be discussing some of these specific LLM vulnerabilities, as well as how to properly mitigate these vulnerabilities, in further depth over the next two blog posts.
Conclusion
LLM technologies are a very exciting new technology with transformative effects on any product. However, as with any kind of technology, there are technical limitations that should be carefully considered before integrating such features into your application.
LLMs are error-prone and overly trusting. As such, any data or input that is fed to the LLM should be carefully considered and architected for, and any data that comes out of the LLM should be properly vetted and sanitized. More so than with any other type of technology, LLMs require careful design to prevent business risk.