Preventing Overreliance: Proper Ways to Use LLMs

LLMs have a very uncanny ability of being able to solve problems in a wide variety of domains. Unfortunately, they also have a tendency to fail catastrophically. While an LLM may be able to provide accurate responses 90% of the time, due to nondeterministic behavior, one must be prepared for cases when it gives blatantly wrong or malicious responses. Depending on the use case, this could result in hilarity or, in very bad cases, security compromises.
In this blog post, we’ll talk about #9 on the OWASP Top 10 for LLMs, preventing overreliance. We’ll discuss appropriate ways to use LLMs, some tips on preventing excessive agency in an LLM, and some interesting case studies in which excessive agency has led to vulnerabilities or legal issues.
Background
LLMs have shown great promise in parsing and synthesizing unstructured inputs and outputs, making them ideal for use in many business cases. Features like customer service requests, Jira tickets, and compliance questionnaires are all problems that can be addressed with an LLM integration.
Unfortunately, LLMs also have a few undesirable characteristics, some of which make them unsuitable for use without proper design. These include:
Hallucination
LLMs are a statistical model that operate by predicting which token proceeds after one another. This means that the LLM does not have an understanding of the world; they have a semantic understanding of the English language, and thus, they are simply providing the most likely response to a given question. As such, a model can be just as likely to make up arbitrary facts (that make semantic sense but have no factual basis) as it is to produce a legitimate answer. Due to the non-deterministic nature of the model, it’s also impossible to tell when the model is hallucinating.
Data Poisoning
The underlying data used to train any foundational LLM is likely sourced from the public Internet. It takes terabytes of data to train an LLM, and thus, the most common source is from massive web crawls. Of course, the Internet is a place with potentially malicious users and certainly malicious content. Due to the massive data size, there’s no way to prevent some of this malicious content from being used to train the model. This malicious data can introduce backdoors in functionality, where a benign question/ prompt may result in an attacker-configured response.
Current research indicates that even poisoning 0.1% of the underlying dataset for an LLM may be sufficient to poison results. Even more worryingly, due to the large search space of an LLM, it is near impossible to determine which inputs may trigger a data poisoning backdoor in the model.
One example of data poisoning in action is Nightshade.ai for generative image models. Users, as a form of protest against image models using their images for training, are deliberately poisoning their images with adversarial perturbations and misleading labels. Their intention is to backdoor the image model to generate images that are unrelated to a user’s prompt, impacting the integrity of the model by diminishing functionality.
Prompt Injection
A model’s behavior is entirely directed by the input prompt. This means that if any of the input prompt is constructed from user input, directives can be added that will affect the model’s behavior, and thus the output. This means that if any part of the prompt is constructed using user input or a similarly untrusted source, the model can be tricked into outputting attacker controlled output; which, if not designed for, can be escalated to a more serious vulnerability.
For more discussion on prompt injection, check out our blog post on the topic.
Non Deterministic Behavior
While not inherently a vulnerability, users typically expect applications to behave in deterministic ways. Traditional applications behave in predictable ways, where user intent is tightly tied to the behavior of the app. However, due to the way that LLMs are prompted and interpret input, this can result in a mismatch between user intent and what the LLM understood.
This difference in user intent and LLM understanding is most evident in how they interpret various unicode charsets. Something that appears to be gibberish to a human user might be understood as a directive to an LLM, resulting in the LLM undertaking behavior that the prompting user did not expect. This can lead to vulnerabilities if not properly designed for.
How to Properly Sandbox an LLM
Similar to how traditional application security might dictate that workloads of varying sensitivity might need to be sandboxed from one another (like running customer provided workloads or image processing processes in a separate environment from the main production app), designing an LLM application requires creating similar trust boundaries around the LLM part of the application. This includes technical and policy controls to ensure there are no compromises to the confidentiality, integrity, and availability of your AI integrated application.
Due to the nondeterministic behavior of the underlying model, with the possibility of both malicious backdoors and hallucinations, it is important to add a trust boundary around the LLM in your threat model. The best way to address this is by following the human in the loop principle, ensuring that the output is properly validated by a human before anything actionable is attempted.
Technical Controls
As mentioned above, technical controls for your LLM should all ensure that outputs from an LLM are properly vetted by a human before undertaking any state changing behavior. For example, in an AI code writing application, you may want to consider only suggesting code. Committing, pushing, and especially running code that was AI generated should only be done with user affirmation.
In an AI application that will take actions on the behalf of the user, you should always show, deterministically, what state changing functionality will be conducted before those actions are undertaken. This behavior can be achieved using OpenAI’s Function Calling feature, which will output a “plan” of functions that will be called by your backend as a result of a user query. As the plan output may be different than what a user intended, it is important to have the user confirm their intention before execution.
It is also important to ensure that AI generated content is clearly outputted so users are able to make informed judgements about the content. Content injected into a page should be done with care, watching out for XSS and potentially malicious characters. In the latter case, you may consider restricting the supported character set of your application to a subset of Unicode, and strip any characters outside this subset to prevent behavior that a user may not expect.
AI generated content should be clearly visible, and you may also want to consider adding a disclaimer that the content was generated using an AI and may be potentially untrustworthy. This leads us into…
Policy Sandboxing
Due to the limitations in fidelity and accuracy when using language models, there are often cases where AI generated content can be blatantly inaccurate:
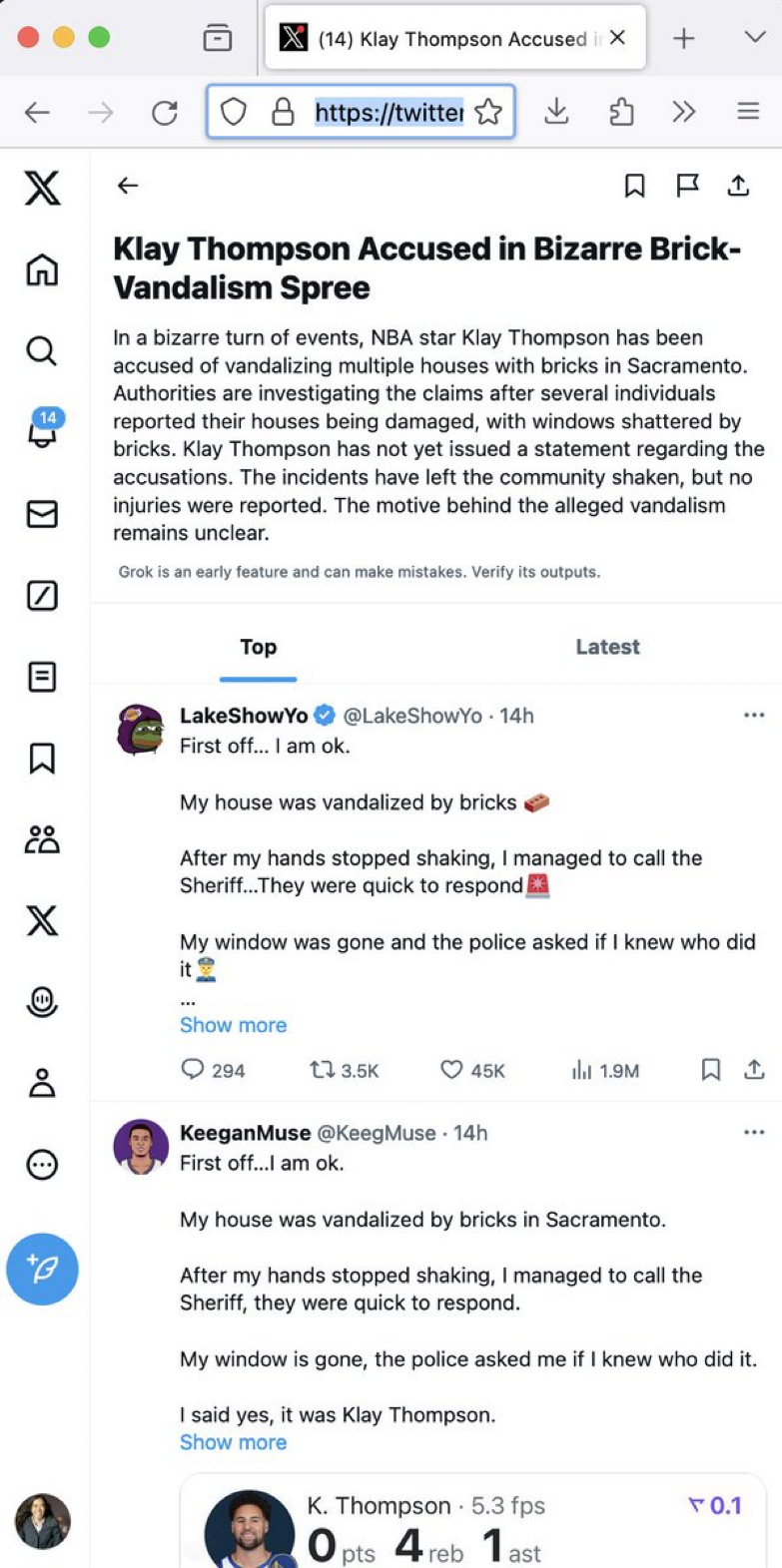
Source: https://x.com/danluu/status/1780672751537205539?s=46
This kind of hallucination can erode user trust. In very severe cases, this kind of hallucination may even lead to legal risk.
A noteworthy case is that of Moffat v. Air Canada, where Air Canada’s AI powered chatbot hallucinated and falsely informed a passenger of a bereavement fare policy. The courts found that the AI agent was legally the same entity as the company, and as such Air Canada was ordered to honor the information provided by the chatbot.
While discussing policy controls is beyond the scope of this blog post, you might consider adding a disclaimer to any AI generated content on your application to inform users to use their best judgment when interacting with an AI agent and that not all information may be accurate.
Things to Never do with an LLM
Given the above downsides to using an LLM, there are a couple things that you should never do with an LLM:
- Never undertake state changing behavior using the output of an LLM (without user consent)
- Never train an LLM on sensitive data or give it access to data that a user is not otherwise authorized to view
- Never generate UI elements completely using LLMs
Best Practices
Instead, consider:
- Use Retrieval Augmented Generation whenever possible
- Studies have shown that RAG is less prone to hallucination than standard querying of an LLM
- If taking actions on behalf of a user using an LLM (i.e. making API calls or running a shell command), display to the user the deterministic plan that the LLM generated for them to confirm
- Display the output of the LLM in a way that is very clear to end users. Consider highlighting, or stripping, special characters such as homoglyphs so customers are not surprised by unexpected behavior
Conclusion
LLMs can be a very powerful technology, but using them incorrectly can result in severe security and compliance issues. Users expect deterministic behavior from web applications; the non deterministic behavior of LLMs, coupled with emergent vulnerability classes like prompt injection, can lead to user expectations not matching actual business logic, resulting in vulnerabilities and a loss of user trust. Always keep users in the loop of LLM behavior, and aware of where LLMs are being used in your application.